Overview of Big Data Architecture
Before we look into the architecture of Big Data, let us take a look at a high level architecture of a traditional data processing management system. It looks as shown below.
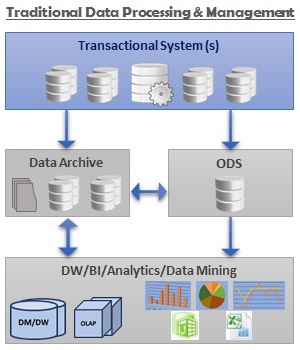
As we can see in the above architecture, mostly structured data is involved and is used for Reporting and Analytics purposes. Although there are one or more unstructured sources involved, often those contribute to a very small portion of the overall data and hence are not represented in the above diagram for simplicity. However, in the case of Big Data architecture, there are various sources involved, each of which is comes in at different intervals, in different formats, and in different volumes. Below is a high level architecture of an enterprise data management system with a Big Data engine.

Let us take a look at various components of this modern architecture.
Source Systems
As discussed earlier there are various different sources of Big Data including Enterprise Data, Social Media Data, Activity Generated Data, Public Data, Data Archives, Archived Files, and other Structured or Unstructured sources.
Transactional Systems
In an enterprise, there are usually one or more Transactional/OLTP systems which act as the backend databases for the enterprise's mission critical applications. These constitute the transactional systems represented above.
Data Archive
Data Archive is collection of data which includes the data archived from the transactional systems in compliance with an organization's data retention and data governance policies, and aggregated data (which is less likely to be needed in the near future) from a Big Data engine etc.
ODS
Operational Data Store is a consolidated set of data from various transactional systems. This acts as a staging data hub and can be used by a Big Data Engine as well as for feeding the data into Data Warehouse, Business Intelligence, and Analytical systems.
Big Data Engine
This is the heart of modern (Next-Generation / Big Data) data processing and management system architecture. This engine capable of processing large volumes of data ranging from a few Megabytes to hundreds of Terabytes or even Petabytes of data of different varieties, structured or unstructured, coming in at different speeds and/or intervals. This engine consists primarily of a Hadoop framework, which allows distributed processing of large heterogeneous data sets across clusters of computers. This framework consists of two main components, namely HDFS and MapReduce. We will take a closer look at this framework and its components in the next and subsequent tips.